Reinventing experience replay: prioritize like humans do
This is my independent research project with Prof. Marcelo Mattar. We aim to design a bias term in addition to the TD-error (prediction error) which was originally used in Prioritized Experience Replay. This bias term, which we call the “need” term, measures the expected future relevance of one state w.r.t. another. The effect we want to achieve is that, given that the agent is at one certain current state, it not only samples the experiences that are most “surprising”, but also most relevant to its near future. Our idea is inspired from human memory replay patterns in Neuroscience, and it resembles the way biological organisms learn from the past experiences.
Intuitively, if I’m preparing for a math exam (current state), I recap those knowledge that I do not fully understand (most surprising, high TD-error). Meanwhile, I only recap knowledge in math (most relevant, high need value), instead of knowledge in physics which seems pretty irrelevant to the exam tomorrow. In this way, I would eventually get better prepared in limited time, and do well in the exam.
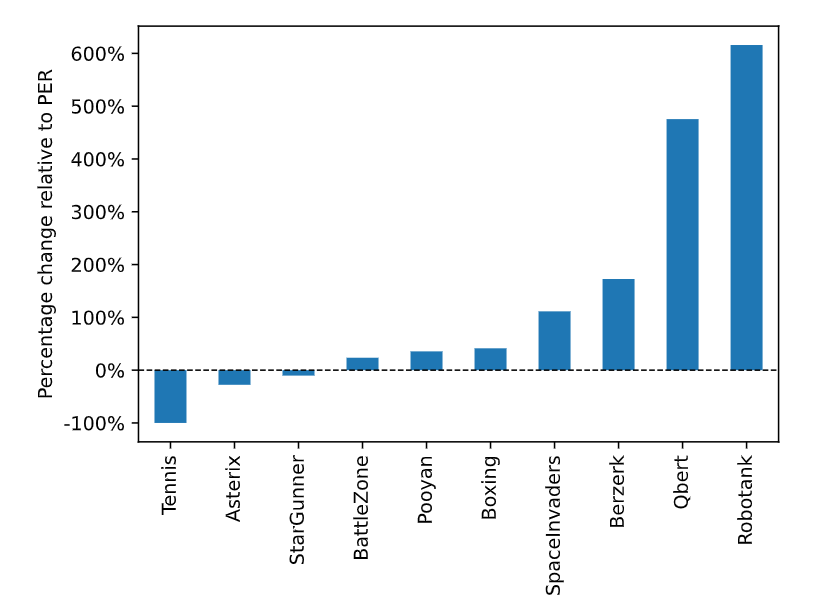
The Successor Representation (SR) is particularly suitable for implementing our proposed term as it is a measurement for future state occupancy. We thus use SR to incorporate this term into Prioritized Experience Replay (PER) based on the deep Q-network (DQN). Our proposed algorithm scores higher in 7 out of 10 Atari games, achieving up to 500% improvement, as shown in the figure below, where bars with positive values indicate improvements.